LeetCode 1573. 分割字符串的方案数(组合数学)
本文共 1231 字,大约阅读时间需要 4 分钟。
题意:
给你一个二进制串 s (一个只包含 0 和 1 的字符串),我们可以将 s 分割成 3 个 非空 字符串 s1, s2, s3 (s1 + s2 + s3 = s)。请你返回分割 s 的方案数,满足 s1,s2 和 s3 中字符 '1' 的数目相同。由于答案可能很大,请将它对 10^9 + 7 取余后返回。数据范围:s[i] == '0' 或者 s[i] == '1'3 <= s.length <= 10^5
解法:
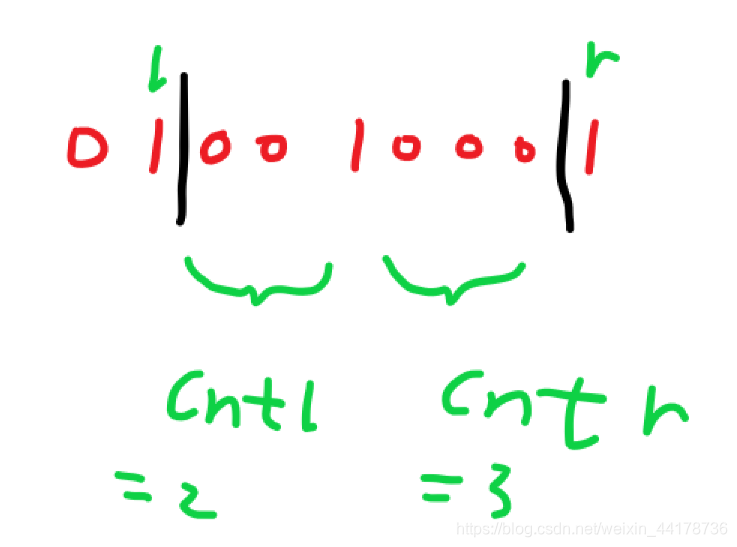
设tot为1的总数量,如果tot=0,那么答案为C(n-1,2),如果tot!=0,那么:设串下标为[1,n],找到满足s[1,l]=tot/3的最小下标l,找到满足s[r,n]=tot/3的最大下标r,然后统计l+1开始到其右边第一个1之间0的数量cntl,以及r-1开始到其左边第一个1之间0的数量cntr.那么答案为(cntl+1)*(cntr+1),因为左边有cntl+1个空隙可以选择,右边有cntr+1个空隙可以选择.如下图:
code:
class Solution { public: static const int maxm=1e5+5; static const int mod=1e9+7; int d[maxm]; int numWays(string s) { memset(d,0,sizeof d); int n=s.size(); s='p'+s; int ans=0; for(int i=1;i<=n;i++){ d[i]=d[i-1]+(s[i]=='1'); } int tot=d[n]; if(tot==0){ return 1ll*(n-1)*(n-2)/2%mod; } if(tot%3)return 0; int l=1; while(d[l]!=tot/3)l++; int r=n; while(d[n]-d[r-1]!=tot/3)r--; int cntl=0,cntr=0; for(int i=l+1;i<=n;i++){ if(s[i]=='0')cntl++; else break; } for(int i=r-1;i>=1;i--){ if(s[i]=='0')cntr++; else break; } return 1ll*(cntl+1)*(cntr+1)%mod; }}; 转载地址:http://igkv.baihongyu.com/
你可能感兴趣的文章
mysql函数汇总之条件判断函数
查看>>
mysql函数汇总之系统信息函数
查看>>
MySQL函数简介
查看>>
mysql函数遍历json数组
查看>>
MySQL函数(转发)
查看>>
mysql分区表
查看>>
MySQL分层架构与运行机制详解
查看>>
mysql分库分表中间件简书_MySQL分库分表
查看>>
MySQL分库分表会带来哪些问题?分库分表问题
查看>>
MySQL分组函数
查看>>
MySQL分组查询
查看>>
Mysql分表后同结构不同名称表之间复制数据以及Update语句只更新日期加减不更改时间
查看>>
mySql分页Iimit优化
查看>>
MySQL分页查询
查看>>
WebDriverException:未知错误:对于旧版本的 Google Chrome,在 Python 中找不到带有 Selenium 的 Chrome 二进制错误
查看>>
mysql列转行函数是什么
查看>>
mysql创建函数报错_mysql在创建存储函数时报错
查看>>
mysql创建数据库和用户 并授权
查看>>
mysql创建数据库指定字符集
查看>>
MySql创建数据表
查看>>